I recently graduated from Aalborg University with Master degree in Computer Science. Since then, Lars Kærlund Østergaard and I, along with our professors Jiri Srba and Kim Guldstrand Larsen published a paper on our work at SPIN 2013. Lars and I attended the conference at Stony Brook University, New York, where I presented the paper. I’ve long planned to write a series of blog posts about these things, but since I started at Mozilla I’ve been way too busy doing other interesting things. I do, however, despise the fact that my paper is hidden behind a pay-wall at Springer. So I feel compelled to use my co-author rights and release the paper here along with a few other documents, that contains proofs and results in greater detail.
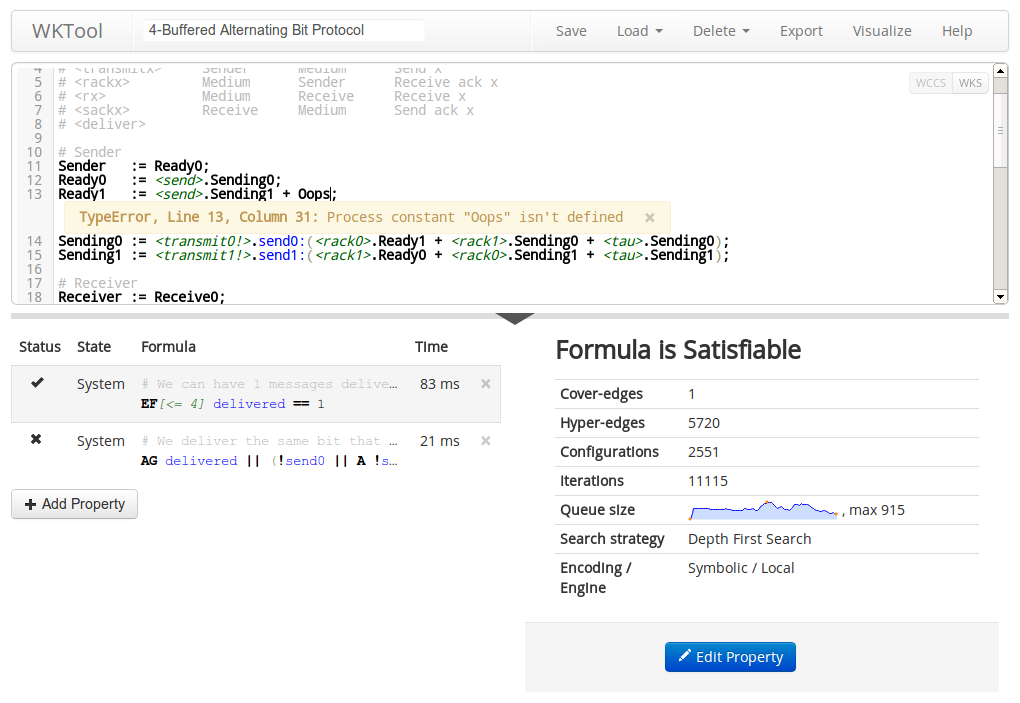
Anyways, as the headline suggests this post is mainly about model checking of Weighted Computation Tree Logic (WCTL) on Weighted Kripke Structures (WKS) in a web browser. To test out the techniques we developed for local model checking, we implemented, WKTool, a browser based model checking tool, complete with graphical user-interface, syntax highlighting, inline error messages, graphical state-space exploration, and of course on-the-fly model checking using Web Workers.
If Kripke structures and branching time logics are foreign concepts to you, this post is probably of limited interest. However, if you’re familiar with the Calculus of Communicating Systems (CCS) as used in various versions of the Concurrency Workbench, this post will give an informal introduction to the syntax of the Weighted Calculus of Communicating Systems (WCCS) and WCTL as using in WKTool.
Weighted Calculus of Communicating Systems
The following table outlines the syntax for WCCS expressions. The concepts are similar to those from Concurrency Workbench, parallel composition allows input and output actions to synchronize, and restriction forces synchronization. However, it maybe observed that actions prefixes also carry a weight. This is the weight of the transition with the action is executed, on synchronization the maximum weight is used (though this is not a technical restriction).
Expression
Syntax
Process Definition
M := P;
Action Prefix
<c,8>.P or <c!,8>.P or <c>.P
Atomic Label
a:P
Parallel Composition
P | Q
Choice
P + Q
Restriction
P \ {c} or P \ {c1, c2, c3}
Renaming
P [a1 => a2, a3 => a4] or P [c1 -> c2, c3 -> c4]
Empty Process
0
As WCCS defines Kripke structures and not Labelled Transistion Systems (LTS) we shall also specify atomic propositions. These are also prefixed with colon, in parallel and choice composition the atomic propositions from both sub-processes are considered. In fact, the action prefix is the only construction from which atomic propositions of the sub-process isn’t considered.
Weighted Computation Tree Logic
The full syntax of WCTL is given in the help section of WKTool, conceptually there are few surprises here. WCTL features boolean operators, atomic proposition and boolean constants as expected. However, for existential and universal until modalities, WCTL adds an optional upper-bound. For example the property E a U[<=8] b holds if there exists a path such that the atomic property a holds until the atomic property b holds, and the accumulated weight at this point does not exceed 8. Similar upper-bound is available for universal until and derived modalities.
For the existential and universal weak-until modalities WCTL offers a lower-bound constraint. For example the property E a W[>=8] b holds if there exists a path such that the atomic property a always holds, or there is a path such that the atomic property a holds until the atomic property b holds and the accumulated weight at this point isn’t less than 8. Observe that the bound has no effect if there is a path where the atomic property a always holds, thus, a zero-cycle might satisfy this property.
In the examples above the nested properties are atomic, however, WKTool does in fact support nested fixed-points when the min-max encoding us used.
Weighted On-The-Fly Model Checking with WKTool
WKTool is hosted at wktool.jonasfj.dk, you can save your models to local storage (in your browser) or export them in a JSON format that can be shared or loaded later. I’m sure most of the features are easy to locate, but do notice that under “Load” > “Load Example” the 4 last examples are the scalable models used for benchmarks in our paper. Try them out, the default scaling parameters are sane and they come with properties that can be verified, some of them even have comments to help you understand what they do.
Yesterday morning, while lying in bed consider whether or not to face the snow outside, I saw a long anticipated entry in gReaderPro (a Google Reader app). I think the release of Google Drive Realtime Api is extremely exciting. The way I see it realtime collaboration is one of the few features that makes browser-based productivity applications preferable to conventional desktop applications.
At University I’ve been using Gobby with other students for years, with a local server the latency is zero, and whether we’re writing a paper in LaTeX or prototyping an algorithm, we’re always doing it in Gobby. It’s simply the best way to do pair programming, or to write a text together, even if you’re not always working on the same section. Futhermore, there’s never a merge conflict 🙂
Needless to say that I started reading the documentation over breakfast. And as luck would have it, Lars, who I’m writing my master with, decided that he’d rather work from home than go through the snow, saving me from having to rush out the door.
Anyways, I found sometime last night to play around with CodeMirror and the new Google Drive Realtime Api. I’ve previously had a look at Firebase, which does something similar, but Firebase doesn’t support operational transformations on strings. In Google Drive Realtime Api this is supported through the CollaborativeString object, which has events and methods for inserting text and removing ranges.
So I extended the Quickstart example to use CodeMirror for editing, after a bit of fiddling around it turned out to be quite easy to adapt the beforeChange event, such that I can all changes on the collaborativeString using insertText and removeRange methods. The following CoffeeScript snippet show how to synchronize an editor and a collaborativeString.
synchronize = (editor, coString) -># Assign initial value
editor.setValue coString.getText()
# Mutex to avoid recursionignore_change = false# Handle local changes
editor.on 'beforeChange', (editor, changeObj) ->returnif ignore_change
from = editor.indexFromPos(changeObj.from)
to = editor.indexFromPos(changeObj.to)
text = changeObj.text.join('\n')
if to - from >0
coString.removeRange(from, to)
if text.length >0
coString.insertString(from, text)
# Handle remote text insertion
coString.addEventListener gapi.drive.realtime.EventType.TEXT_INSERTED, (e) ->from = editor.posFromIndex(e.index)
ignore_change = true
editor.replaceRange(e.text, from, from)
ignore_change = false# Handle remote range removal
coString.addEventListener gapi.drive.realtime.EventType.TEXT_DELETED, (e) ->from = editor.posFromIndex(e.index)
to = editor.posFromIndex(e.index + e.text.length)
ignore_change = true
editor.replaceRange("", from, to)
ignore_change = false
So a few things I learned from this exercise, use or at least study the code samples, much of it isn’t documented and the documentation can be a bit fragmented. In particular realtime-client-utils.js was really helpful to get this off the ground.
Lately, I’ve been working an web application which will need to save binary blobs inside JSON objects. Looking around the web it seems that base64 encoding is the method of choice in these cases. However, this adds a 30% overhead and decoding large base64 strings to Javascript typed arrays (ArrayBuffer) is an expensive tasks.
So I’ve been looking at different binary data formats: BSON, Protocol Buffers, Smile Format, UBJSON, BJSON and others. Eventually, I decided to give BJSON a try for the following reasons.
BJSON is easy to make a lightweight implementation
It can encapsulate any JSON object
BJSON documents can be represented as JSON objects with ArrayBuffers for binary blobs.
My primary motivation is the fact that BJSON can serialize ArrayBuffers, as an added bonus a BJSON encoding of JSON object is typically smaller than the traditional string encoding with JSON.stringify(). Now, I’m sure there is valid arguments to use another binary encoding of JSON objects, so I’m going to stop with the arguments and talk code instead…
Well, time to introduce BJSON.coffee, a CoffeeScript implementation of BJSON for modern browsers. Aparts from null, booleans, numbers, arrays and dictionaries also available JSON, the BJSON specification also defines the inclusion of binary data. The specification notes that “this is not fully transcodable“, but as you might have guessed BJSON.coffee uses ArrayBuffers to represent binary data.
Essentially, BJSON.serialize takes a JSON object that is allowed to contain ArrayBuffers and serializes to a single ArrayBuffer. While, BJSON.parse takes an ArrayBuffer and returns a JSON object which may contain ArrayBuffers.For those interested in using BJSON instead of a normal string encoding of JSON objects, there is both good and bad news. The bad news is that UTF-8 string encoding in modern browsers is so slow, that BJSON is slower than a conventional string encoding of JSON objects. Although, this might not be the case when/if the string encoding specification is implemented.
The good news is that the BJSON encoding is 5-10% smaller than the conventional string encoding of JSON objects. The table/terminal output below from my testing script, shows some common JSON objects harvested from common web APIs.
BJSON.coffee is available at github.com/jonasfj/BJSON.coffee. It should work in all modern browsers with support for typed arrays, Firefox 15+, Chrome 22+, IE 10+, Opera 12.1+, Safari 5.1+. However, I have pushed a github page which runs unit-tests in the browser and shows compatibility results from other browsers using Browserscope. So please visit it here, click “run tests” and help figure out where BJSON.coffee works.
Update: Being bored today I decided to a quick jsperf benchmark of JSON.stringify and BJSON.serialize to see how much slower BJSON.serialize is. You can find the test here, which seems to suggest that BJSON.serialize might be unreasonably slow at the moment. However, it seems that slow UTF-8 encoding is responsible for much of this, and I believe it is possible to improve the current UTF-8 encoding speed.
Back in high school I started TheLastRipper, an audio stream recorder for last.fm. The project started as product for a school project on copyright and issues with piracy. It spawn from the unavailability of non-DRM infested music services. Which at the time drove many teenagers to piracy. Whilst, you the morality of recording internet radio can be argued. All the research we did at the time, showed it to be perfectly legal. Nevertheless, I’m quite happy that I didn’t have to defend this assertion.
Anyways, I’m glad to see that the music industry didn’t sleep for ever. These days we have digital music stores and I’m quite happy to pay for DRM-free music, and as bonus I get to support the artists as well. So it can hardly comes as surprise that I haven’t used TheLastRipper for years. Nor have I contributed to the project or attended bug reports for years. In fact it has been years since the project saw any active development.
I do occasionally get an email or see a bug report from an die-hard user of TheLastRipper, and it’s in the wake of such an email I’ve decide write this post. Partly because more people will ask why it stopped working, and partly because I had a lot of fun with project and it deserves a final post here at the end. Personally, I’ve long thought the project dead, I know the Linux client have been, so I was surprised to that anybody actually noticed it when the Radio API was updated.
As you may have guessed from the title of this post TheLastRipper has died from being unmaintained while last.fm have updated their APIs. Honestly, I’m quite surprised last.fm have continued to support their old unofficial API for as long as they have. So this is by no means the result of last.fm taking action against TheLastRipper. Truth be told, I’m not even sad that it’s finally dead. The past many years, state of TheLastRipper have been quite embarrassing. The code base is ugly, buggy and completely unmaintainable.
Over the years, TheLastRipper have been downloaded more than 475.000 times, distributed with magazines (Computer Bild) and featured in countless blog posts from around the world. Which, considering that this started as a high school project is pretty good. It’s certainly been a great adventure and I’ve worked with a lot of people from around the world. So here at the of my last post on TheLastRipper, I’d like to say thanks to all the bug reporters, comment posters, testers, developers and people who hopefully also had fun participating in this project.
Oh, and to the few die-hard users out there, I’ll recommend that you buy your digital music from one of the many DRM-free music stores you can find 🙂
A couple of weeks I introducedTriLite, an Sqlite extension for fast string matching. TriLite is still very much under active development and not ready for general purpose use. But over the past few weeks I’ve integrated TriLite into DXR, the source code indexing tool I’ve been working on during my internship at Mozilla. So it’s now possible to search mozilla-central using regular expressions, for an example regexp:/(?i)bug\s+#?[0-9]+/ to find references to bugs.
For those interested, I did my end-of-internship presentation of DXR last Thursday, it’s currently available on air.mozilla.org (I’m third on the list, also posted below). I didn’t reharse it very much so appoligies if it’s doesn’t make any sense. What does make sense however, is that fact that dxr.allizom.org supports substring and regular expression searches, so fast that we can facilitate incremental search.
(My end-of-internship presentation, slides available here)
Anyways, as you might have guessed from the fact that I gave an end-of-internship presentation, my internship is coming to an end. I’ll be flying home to Denmark next Saturday to finish my masters. But I’ll probably continue to actively develop TriLite and make sure this project reaches a level where it can be reused by others. I’ve already seen other suggestions for where substring search could be useful.
The past two weeks I’ve been working on regular expression matching for DXR. For those who doesn’t know it, DXR is the source code cross referencing tool I’m working on during my internship at Mozilla. The idea is to make DXR faster than grep and support full featured regular expressions, such that it can eventually replace MXR. The current search feature in DXR uses the FTS (Full Text Search) extension for Sqlite, with a specialized tokenizer. However, even with this specialized tokenizer DXR can’t do efficient substring matching, nor is there any way to accelerate regular expression matching. Which essentially means DXR can’t support these features, because full table scans are too slow on a server that serves many users. So to facilitate fast string matching and allow restriction on other conditions (ie. table joins), I’ve decided to write an Sqlite extension.
Introducing TriLite, an inverted trigram index for fast string matching in Sqlite. Given a text, a trigram is a substring of 3 characters, the inverted index maps from each trigram to a list of document ids containing the trigram. When evaluating a query for documents with a given substring, trigrams are extracted from the desired substring, and for each such trigram a list of document ids is fetched. Document ids present in all lists are then fetched and tested for the substring, this reduces the number of documents that needs to fetched and tested for the substring. The approach is pretty much How Google Code Search Worked. In fact, TriLite uses re2 a regular expression engine written by the guy who wrote Google Code search.
TriLite is very much a work in progress, currently, it supports insertion and queries using substring and regular expression matching, updates and deletes haven’t been implemented yet. Anyways, compared to the inverted index structure used in the FTS extension, TriLite has a fairly naive implementation, that doesn’t try to provide a decent amortized complexity for insertion. This means that insertion can be rather slow, but maybe I’ll get around to try and do something about that later.
Nevertheless, with the database in memory I’ve been greping over the 60.000 files in mozilla-central in about 30ms. With an index overhead of 80MiB for the 390MiB text in mozilla-central, the somewhat naive inverted index implementation employed in TriLite seems pretty good. For DXR we have a static database so insertion time is not really an issue, as the indexing is done on an offline build server.
As the github page says, TriLite is no where near ready for use by anybody other than me. I’m currently working to deploy a test version of DXR with TriLite for substring and regular expression matching. Something I’m very much hoping to achieve before the end of my internship at Mozilla. So stay tuned, a blog post will follow…
This year I’m spending my summer vacation interning at the Mozilla office in Toronto. The past month I’ve been working on DXR, a source code indexing and cross referencing application. So far I’ve worked to deploy DXR on Mozilla infrastructure and is happy to report that dxr.mozilla.org is no longer redirecting to dxr.lanedo.com. The releng team have a build bot indexing mozilla-central, so that we always have a fresh index on dxr.mozilla.org. So in blind faith that this will never crash horribly, I’ll tell to:
Whilst I’ve been handling most of the deployment issues, the releng team have been doing the heavy lifting when comes to automatic build, thanks! This means, that I’ve been working on cleaning up, refactoring, redesigning and rewriting parts of DXR. This sounds like a lot of behind the scenes work that nobody will ever see, however, this means that DXR now has a decent template system. And well, who would I be if I didn’t write a template for it.
You can find the tip of DXR that I’m working on at dxr.allizom.org, please check out it and let me know if there’s something you don’t like and would like to appear. I realize that the site currently have a few crashes, and don’t worry I won’t rush this into production before I’ve ratted these out. Now, as evident from this blog, I’m by no means a talented designer, so if you feel that grey should be red or whatever, please leave a color code in the comments and I’ll try it out.
I’m currently looking into replacing the full text search and my somewhat buggy text tokenizer with a trigram index that’ll facilitate proper substring matching and if we lucky regular expression matching. But I guess we will have to wait and see how that turns out. In the mean time leave a comment if you have questions, requests, suggestions and/or outcries.
I can’t say that I have been very active on this blog the past couple of years, nevertheless when I decided to hack a little on theme this morning I found an infestation of hidden links to all sorts of crap. Apparently this sort of thing is not unheard of on wordpress blog.
Anyways, I’ve been planning to slowly out phase the “jopsen” nickname, and having recently bought “jonasfj.dk” I decided to do an export of my wordpress blog. Setup a new one on a new domain. Dreamhost one click install made this rather easy, and I now have automatic wordpress updates.
My old domain “jopsen.dk” will now redirect to “jonasfj.dk”, and I’ve deleted the infected wordpress install. I still have a wiki running on the old domain, but it’s no longer active, so if possible I plan to render it static, at which point I’ll move it from the domain.
This does not mean that I’ll get all rid of the “jopsen” nickname, I’ve got many accounts under that name. But in the future I’ll try to move some of the frequently used accounts to “jonasfj”. I think it’s a little more sensible and gives sort of a hit about who I might be 🙂 Update: Changed my github username from jopsen to jonasfj. Well I think that’s all the renaming I can handle for now.
With respect to the “pharma hack” I think it’s sad that we live in a world where some people have so little respect for my time. After all the ad-space on my blog has no value compared to the costs of cleaning up after this. Worst of all is that these links where hidden, I only discovered them by accident, and I have no idea how long time they’ve there.
Anyways, I’ve disabled ftp, used a different domain, different shell user, clean wordpress install with a Google Authenticator plugin. At least that’s a start.
Whilst gedit isn’t the fastest, smartest or most fancy editor out there, I often find my self using it. With toolbars hidden and menu bar gone (unity), gedit is a neat little thing. It always works, and whilst it lacks many features compared to vim, the features gedit does offer, never pops up because I accidentally pressed some key.
The one thing about gedit that I do however feel is missing, is the ability to modify shortcuts. For example switching tabs with “Ctrl + Tab” and “Ctrl + Shift + Tab”, and closing tabs with “Ctrl + F4”, feels as natural as browsing the web in Firefox.
Luckily, it’s possible to install plugins for gedit, I recently found a plugin call Control Your Tabs, that allows you to switch tabs with “Ctrl + Tab”. However, it does tab switch in most recently used order, instead of switching tabs by order in tabview.
I had a quick look at the source for Control Your Tabs, which turned out to be slightly complicated. While I could hack the source to fit my needs, it turned out to be faster and simpler to just write my own gedit plugin.
So here it is TabControl, 50 lines of python now hosted at github.
The plugin switches tabs with “Ctrl (+ Shift) + Tab” based on their order in the tabview. And on top of this it allows you to close the current tab using “Ctrl + F4”. You can find files and installation instructions in the github repository.
The plugin is really short and simple, so if you want a shuffle feature for switch tabs (or whatever), this could be a good place to start. Otherwise I’d definitely recommend taking a look at the gedit plugin documentation.
A few days ago a diploma dropped in the door, meaning that after 3 years at Aalborg University I’ve got a “Bachelor of Science (BSc) in Computer Science”, as it says on the paper… I’m of course continuing as a master student next – no reason to get out “there” in the real world, where you have to work, assuming you don’t what to starve 🙂
Anyways, it occurred to me that I haven’t blogged about my Bachelor project. So I better get it done now, as I’m off for vacation in California later tonight… This semester we worked in groups of 3, and was supposed to write a 12-20 pages article, as opposed to a 100-200 pages report. Which turned out to be quite challenging, but also somewhat nice, because we got to polish every sentence.
As the title of the post indicates we did a project about Petri nets, a very simple but powerful modeling language. To achieve a “feeling” of novelty we introduced global discrete variables, that you can condition on and modify in transitions, and called our new model for Petri nets With Discrete Variables (PNDV). Whilst, to my knowledge, this have not been done before, we didn’t focus on showing that PNDVs where particularly useful for any specific purpose. So that part of the project feels a little shoehorned, at least to me, and maybe only me, because we all got an A for the project.
Nevertheless, assuming that the PNDV model (we invented) is interesting, then the graphical Petri net editor and verification tool we wrote during this project might also be interesting. In a desperate search for a name we came up with PeTe, yes is spelled pretty weird, but also quite cute 🙂
Given a PNDV or Petri net PeTe can determine if a state satisfying a given formula is possible. This problem is very hard (EXPSPACE-hard), but we had a lot of fun writing different search strategies for exploring the state space of a PNDV. Most notably we found that even quite simple heuristics can provide a huge performance improvement by guiding a search in state space. We also had great success with over-approximation, by using state equation and trap testing to disprove the satisfyability of a formula.
The heuristics and methods implemented in PeTe is presented in the article we wrote, available for download below. This article also present some, in my opinion, rather shoehorned results, like translation from Discrete Timed Arc Petri Net to PNDV. I also can’t help but feel that the direction and goal in the article could have been more clear. But done is done, and I’m off to vacation when I’ve added some links 🙂