|
|
Jonasfj.dk/Blog
A blog by Jonas Finnemann Jensen
December 29, 2017 Templating JSON/YAML with json-e
Many systems are configured using JSON (or YAML), and there is often a need to parameterize such configuration. Examples include: AWS CloudFormation, Terraform, Google Cloud Deployment Manager, Taskcluster Tasks/Hooks, the list goes on.
This paramterization is usually accomplished with one of the following approaches:
- Use of custom variable injection syntax and special rules,
- Rendering with a string templating engine like jinja2 or mustache prior to parsing the JSON or YAML configuration, or,
- Use of a general purpose programming language to generate the configuration.
Approach (1) is for example used by AWS CloudFormation and Terraform. In Terraform variables can be injected with string interpolation syntax, e.g. ${var.my_variable}, and resource objects with a count = N property are cloned N times. Drawbacks of this is that each system have its own logic and rules that you’ll have to learn. Often these are obscure, verbose and/or inconsistent, as template language design isn’t the main focus of a project like Terraform or CloudFormation.
Approach (2) is among other places used in Google Cloud Deployment Manager, it was also employed in earlier versions of .taskcluster.yml. For example in Google Cloud Deployment Manager your infrastructure configuration file is rendered using jinja2 before being parsed as YAML. Which allows you to make a parameterized infrastructure configuration. While this approach reuse existing template logic, drawbacks include the fact that after passing through the text template engine your JSON or YAML may no longer parse due to whitespace issues, commas or other terminals accidentally injected. If the template is big, this is easy to do, resulting in errors that are hard to understand and track down.
Approach (3) is for example used by vagrant where config files are written in Ruby. It’s also used in gecko where moz.build files written in Python define which source files to compile. This approach is powerful, and reuse existing established languages. Drawbacks of this approach is that you need sandboxing to read untrusted config files. This approach also binds you to a specific programming language, or at-least forces you to have an interpreter for said language installed. Finally, there can be cases where these, often imperative configuration files becomes clutter and littered with if-statements.
Introducing json-e
json-e is a language for parameterization of JSON following approach (1), which is to say you can write your json-e template as JSON, YAML or anything that translates to a JSON object structure in-memory. Then the JSON structure can be rendered with json-e, meaning interpolation of variables and evaluation of special constructs.
An example is probably the best way to understand json-e, below is a javascript example of how json-e works.
let template = {
title: 'Testing ${name}',
command: [
'go', 'test', {
$if: 'verbosity > 0',
then: '-v'
}
],
env: {
GOOS: '${targetPlatorm}',
CGO_ENABLED: {
$if: 'cgo',
then: '1',
else: '0'
},
BUILDID: {$eval: 'uuid()'}
}
};
let context = {
name: 'my-package',
verbosity: 0,
targetPlatorm: 'linux',
cgo: false,
uuid: () => uuid.v4(),
};
let result = jsone.render(template, context);
/*
* {
* title: 'Testing my-package',
* command: [
* 'go', 'test'
* ],
* env: {
* GOOS: 'linux',
* CGO_ENABLED: '0',
* BUILDID: '3655442f-03ab-4196-a0e2-7df62b97050c'
* }
* }
*/
Most of the variable interpolation here is obvious, but constructs like {$if: E, then: A, else: B} are very powerful. Here E is an expression while A and B are templates. Depending on the expression the whole construct is replaced with either A or B, if either one of those are omitted the parent property or array index is deleted.
As evident from the example above json-e contains an entire expression language. This allows for complex conditional constructs and powerful variable injection. Aside from the expression language json-e defines a set of constructs. These are objects containing a special keyword property that always starts with $. The conditional $if is one such construct. These constructs allows for evaluation of expressions, flattening of lists, merging of objects, mapping elements in a list and many other things.
The constructs are first interpreted after JSON parsing. Hence, you can write json-e as YAML and store it as JSON. In fact, I would recommend writing json-e using YAML as this is very elegant. For a full reference of all the constructs, built-in functions, and expression language features checkout the json-e documentation site, it even includes an interactive json-e demo tool.
Design Choices
Unlike the special constructs and syntax used in AWS CloudFormation and Terraform, json-e aim to be a general purpose JSON parameterization engine. So ideally, json-e can be reused in other projects. The design is largely guided by the following desires:
- Familiarity to Python and Javascript developers,
- Injection of variables after parsing JSON/YAML,
- Safe rendering without need for OS-level sandboxing,
- Extensibility by injection of functions as well as variables,
- Avoid Turing completeness to prevent templates from looping forever,
- Side-effect free results (baring side-effects in injected functions),
- Implementation in multiple languages.
We wanted safe rendering because it allows for services like taskcluster-github to render untrusted templates from .taskcluster.yml files. Similarly, we wanted implementations in multiple languages to avoid being tied to specific programming language, but also to facilitate web-based tools for debugging json-e templates.
State of json-e Today
As of writing the json-e repository contains and implementation of json-e in Javascript, Python and golang, along with a large set of test cases to ensure compatibility between the implementations. Writing a json-e implementation is fairly straight forward, so new implementations are likely to show up in the future.
For those interested in the details I recommend reading about Pratt-parsers, which have made implementation of the same interpreter in 3 languages fairly easy.
Today, json-e is already used in-tree (in gecko), we use it as part of the interface for expressing actions and be triggered in the automation UI. For those interested there is the in-tree documentation and the actions.json specification. We also have plans to use json-e for a few other things including github integration and taskcluster-hooks.
As for stability we may add new construct and functions json-e in the future, but major changes are not planned. For obvious reasons we don’t want to break backwards compatibility, this have happened a few times initially, mostly to correct things that were unintended design flaws. We still have a few open issues like unicode handling during string slicing. But by now we consider json-e stable.
On a final note I would like to extend a huge thanks to the many contributors who have worked on json-e, as of writing the github repository already have commits from 12 authors.
August 13, 2015 Getting Started with TaskCluster APIs (Interactive Tutorials)
When we started building TaskCluster about a year and a half ago one of the primary goals was to provide a self-serve experience, so people could experiment and automate things without waiting for someone else to deploy new configuration. Greg Arndt (:garndt) recently wrote a blog post demystifying in-tree TaskCluster scheduling. The in-tree configuration allows developers to write new CI tasks to run on TaskCluster, and test these new tasks on try before landing them like any other patch.
This way of developing test and build tasks by adding in-tree configuration in a patch is very powerful, and it allows anyone with try access to experiment with configuration for much of our CI pipeline in a self-serve manner. However, not all tools are best triggered from a post-commit-hook, instead it might be preferable to have direct API access when:
- Locating existing builds in our task index,
- Debugging for intermittent issues by running a specific task repeatedly, and
- Running tools for bisecting commits.
To facilitate tools like this TaskCluster offers a series of well-documented REST APIs that can be access with either permanent or temporary TaskCluster credentials. We also provide client libraries for Javascript (node/browser), Python, Go and Java. However, being that TaskCluster is a loosely coupled set of distributed components it is not always trivial to figure out how to piece together the different APIs and features. To make these things more approachable I’ve started a series of interactive tutorials:
All these tutorials are interactive, featuring a runtime that will transpile your code with babel.js before running it in the browser. The runtime environment also exposes the require function from a browserify bundle containing some of my favorite npm modules, making the example editors a great place to test code snippets using taskcluster or related services.
Happy hacking, and feel free submit PRs for all my spelling errors at github.com/taskcluster/taskcluster-docs.
April 1, 2015 Playing with Talos in the Cloud
As part of my goals this quarter I’ve been experimenting with running Talos in the cloud (Linux only). There are many valid reasons why we’re not already doing this. Conventional wisdom dictates that visualized resources running on hardware shared between multiple users is unlikely to have consistent performance profile, hence, regressions detection becomes unreliable.
Another reason for not running performances tests in the cloud, is that a cloud server is very different from a consumer laptop, and changes in performance characteristic may not reflect the end-user experience.
But when all the reasons for not running performance testing in the cloud have been listed, and I’m sure my list above wasn’t exhaustive. There certainly is some benefits to using the cloud, on-demand scalability and cost immediately springs to mind. So investigating the possibility of running Talos in the cloud is interesting, if not thing more it could be used for fast smoke tests.
Comparing Consistency of Instance Types
First thing to evaluate is the consistency of results depending on instance-type, cloud provider and configuration. For the purpose of these experiments I have chosen instances and cloud providers:
- AWS EC2 (m3.medium, m3.xlarge, m3.2xlarge, c4.large, c4.xlarge, c4.2xlarge, c3.large, c3.xlarge, c3.2xlarge, r3.large, r3.xlarge, g2.2xlarge)
- Azure (A1, A2, A3, A4, D1, D2, D3, D4)
- Digital Ocean (1g-1cpu, 2g-2cpu, 4g-2cpu, 8g-4cpu)
For AWS I tested instances in both us-east-1 and us-west-1 to see if there was any difference of results. In each case I have been using two revisions c448634fb6c9 which doesn’t have any regressions and fe5c25b8b675 which has clear regressions in test suites cart and tart. In each case I also ran the tests with both xvfb and xorg configured with dummy video and input drivers.
To ease deployment and ensure that I was using the exact same binaries across all instances I packaged Talos as a docker image. This also ensured that I could reset the test environment after each Talos invocation. Talos was invoked to run as many of the test suites as I could get working, but for the purpose of this evaluation I’m only considering results from the following suites:
- tp5o,
- tart,
- cart,
- tsvgr_opacity,
- tsvgx,
- tscrollx,
- tp5o_scroll, and
- tresize
After running all these test suites for all the configurations of instance type, region and display server enumerated above, we have a lot of data-points on the form results(cfg, rev, case) = (r1, r2, ..., rn), where ri is the measurement from the i’th iteration of the Talos test case case.
To compare all this data with the aim of ranking configurations by the consistency of their results, compute rank(cfg, rev, case) as the number of configurations cfg' where rank(cfg', rev, case) < rank(cfg, rev, case). Informally, we sort configurations based lowest standard deviation for a given case and rev and the index of a configuration in that list is the rank rank(cfg, rev, case) of the configuration for the given case and rev.
We then finally list configurations by score(cfg), which we compute as the mean of all ranks for the given configuration. Formally we write:
score(cfg) = mean({rank(cfg, rev, case) | for all rev, case})
Credits for this methodology goes to Roberto Vitillo, who also suggested using trimmed mean, but as it turns out the ordering is pretty much the same.
When listing configurations by score as computed above we get the following ordered lists of configurations. Notice that the score is strictly relative and doesn’t really say much. The interesting aspect is the ordering.
Warning, the score and ordering has nothing to do with performance. This strictly considers consistency of performance from a Talos perspective. This is not a comparison of cloud performance!
Provider: InstanceType: Region: Display: Score:
aws, c4.large, us-west-1, xorg, 11.04
aws, c4.large, us-west-1, xvfb, 11.43
aws, c4.2xlarge, us-west-1, xorg, 12.46
aws, c4.large, us-east-1, xorg, 13.24
aws, c4.large, us-east-1, xvfb, 13.73
aws, c4.2xlarge, us-west-1, xvfb, 13.96
aws, c4.2xlarge, us-east-1, xorg, 14.88
aws, c4.2xlarge, us-east-1, xvfb, 15.27
aws, c3.large, us-west-1, xorg, 17.81
aws, c3.2xlarge, us-west-1, xvfb, 18.11
aws, c3.large, us-west-1, xvfb, 18.26
aws, c3.2xlarge, us-east-1, xvfb, 19.23
aws, r3.large, us-west-1, xvfb, 19.24
aws, r3.large, us-west-1, xorg, 19.82
aws, m3.2xlarge, us-west-1, xvfb, 20.03
aws, c4.xlarge, us-east-1, xorg, 20.04
aws, c4.xlarge, us-west-1, xorg, 20.25
aws, c3.large, us-east-1, xorg, 20.47
aws, c3.2xlarge, us-east-1, xorg, 20.94
aws, c4.xlarge, us-west-1, xvfb, 21.15
aws, c3.large, us-east-1, xvfb, 21.25
aws, m3.2xlarge, us-east-1, xorg, 21.67
aws, m3.2xlarge, us-west-1, xorg, 21.68
aws, c4.xlarge, us-east-1, xvfb, 21.90
aws, m3.2xlarge, us-east-1, xvfb, 21.94
aws, r3.large, us-east-1, xorg, 25.04
aws, g2.2xlarge, us-east-1, xorg, 25.45
aws, r3.large, us-east-1, xvfb, 25.66
aws, c3.xlarge, us-west-1, xvfb, 25.80
aws, g2.2xlarge, us-west-1, xorg, 26.32
aws, c3.xlarge, us-west-1, xorg, 26.64
aws, g2.2xlarge, us-east-1, xvfb, 27.06
aws, c3.xlarge, us-east-1, xvfb, 27.35
aws, g2.2xlarge, us-west-1, xvfb, 28.67
aws, m3.xlarge, us-east-1, xvfb, 28.89
aws, c3.xlarge, us-east-1, xorg, 29.67
aws, r3.xlarge, us-west-1, xorg, 29.84
aws, m3.xlarge, us-west-1, xvfb, 29.85
aws, m3.xlarge, us-west-1, xorg, 29.91
aws, m3.xlarge, us-east-1, xorg, 30.08
aws, r3.xlarge, us-west-1, xvfb, 31.02
aws, r3.xlarge, us-east-1, xorg, 32.25
aws, r3.xlarge, us-east-1, xvfb, 32.85
mozilla-inbound-non-pgo, 35.86
azure, D2, xvfb, 38.75
azure, D2, xorg, 39.34
aws, m3.medium, us-west-1, xvfb, 45.19
aws, m3.medium, us-west-1, xorg, 45.80
aws, m3.medium, us-east-1, xvfb, 47.64
aws, m3.medium, us-east-1, xorg, 48.41
azure, D3, xvfb, 49.06
azure, D4, xorg, 49.89
azure, D3, xorg, 49.91
azure, D4, xvfb, 51.16
azure, A3, xorg, 51.53
azure, A3, xvfb, 53.39
azure, D1, xorg, 55.13
azure, A2, xvfb, 55.86
azure, D1, xvfb, 56.15
azure, A2, xorg, 56.29
azure, A1, xorg, 58.54
azure, A4, xorg, 59.05
azure, A4, xvfb, 59.24
digital-ocean, 4g-2cpu, xorg, 61.93
digital-ocean, 4g-2cpu, xvfb, 62.29
digital-ocean, 1g-1cpu, xvfb, 63.42
digital-ocean, 2g-2cpu, xorg, 64.60
digital-ocean, 1g-1cpu, xorg, 64.71
digital-ocean, 2g-2cpu, xvfb, 66.14
digital-ocean, 8g-4cpu, xvfb, 66.53
digital-ocean, 8g-4cpu, xorg, 67.03
You may notice that the list above also contains the configuration mozilla-inbound-non-pgo which has results from our existing infrastructure. It is interesting to see that instances with high CPU exhibits lower standard deviation. This could be because their average run-time is lower, so the standard deviation is also lower. It could also be because they consist of more high-end hardware, SSD disks, etc. Higher CPU instances could also be producing better results because they always have CPU time available.
However, it’s interesting that both Azure and Digital Ocean instances appears to produce much less consistent results. Even their high-performance instances. Surprisingly, the data from mozilla-inbound (our existing infrastructure) doesn’t appear to be very consistent. Granted that could just be a bad run, we would need to try more revisions to say anything conclusive about that.
Unsurprisingly, it doesn’t really seem to matter what AWS region we use, which is nice because it just makes our lives that much simpler. Nor does the choice between xorg or xvfb seem to have any effect.
Comparing Consistency Between Instances
Having identified the Amazon c4 and c3 instance-types, as the most consistent classes, we now proceed to investigate if results are consistent when they are computed using difference instances of the same type. It’s well known that EC2 has bad apples (individual machines that perform badly), but this is a natural thing in any large setting. What we are interested in here is what happens when we compare results different instances.
To do this we take the two revisions c448634fb6c9 which doesn’t have any regressions and fe5c25b8b675 which does have a regression in cart and tart. We run Talos tests for both revisions on 30 instances of the same type. For this test I’ve limited the instance-types under consideration to c4.large and c3.large.
After running the tests we now have results on the form results(cfg, inst, rev, suite, case) = (r1, r2, ... rn) where ri is the result from the i’th iteration of the given test case under the given test suite, revision, configuration and instance. In the previous section we didn’t care which suite the test case belonged to. We care about suite relationship here because we compute the geometric mean of the medians of all test cases per suite. Formally we write:
score(cfg, inst, rev, suite) = geometricMean({median(results(cfg, inst, rev, suite, case)) | for all case})
Credits to Joel Maher for helping figure out how the current infrastructure derives per suite performance score for a given revision.
We then plot the scores for all instances as two bar-chart series one for each revision. We get the following plots. I’ve only included 3 here for brevity. Each pair of bars is results from one instance on different revisions, the ordering here is not relevant.
From these two plots it’s easy to see that there is a there is a tart regression. Clearly we can also see that performance characteristics does vary between instances. Even in the case of tart it’s evident, but it’s still easy to see the regression.
Now when we consider the chart for tresize it’s very clear that performance is different between machines. And if a regression here was small, it would be hard to see. Most of the other charts are somewhat similar, I’ve posted a link to all of them below along with references to the very sketchy scripts and hacks I’ve employed to run these tests.
Next Steps
While it’s hard to conclude anything definitive without more data. It seems that the C4 and C3 instance-types offers fairly consistent result. I think the next step is to setup a subset of Talos tests running silently along side existing tests while comparing results to regressions observed elsewhere.
Hopefully it should be possible to use a small subset of Talos tests to detect some regressions early. Rather than having all Talos regressions detected 12 pushes later. Setting this up is not going to a Q2 goal for me, but I should be able to set it up on TaskCluster in no time. At this point I think it’s mostly a configuration issue, since I already have Talos running under docker.
The hard part is analyzing the resulting data and detect regressions based on it. I tried comparing results with approaches like students t-tests. But there is still noisy tests that have to be filtered out, although preliminary findings were promising. I suspect it might be easiest to employ some naive form of Machine learning, and hope that magically solves everything. But we might not have enough training data.
August 11, 2014 Using Aggregates from Telemetry Dashboard in Node.js
When I was working on the aggregation code for telemetry histograms as displayed on the telemetry dashboard, I also wrote a Javascript library (telemetry.js) to access the aggregated histograms presented in the dashboard. The idea was separate concerns and simplify access to the aggregated histogram data, but also to allow others to write custom dashboards presenting this data in different ways. Since then two custom dashboards have appeared:
Both of these dashboards runs a cronjob that downloads the aggregated histogram data using telemetry.js and then aggregates or analyses it in an interesting way before publishing the results on the custom dashboard. However, telemetry.js was written to be included from telemetry.mozilla.org/v1/telemetry.js, so that we could update the storage format, use a differnet data service, move to a bucket in another region, etc. I still want to maintain the ability to modify telemetry.js without breaking all the deployments, so I decided to write a node.js module called telemetry-js-node that loads telemetry.js from telemetry.mozilla.org/v1/telemetry.js. As evident from the example below, this module is straight forward to use, and exhibits full compatibility with telemetry.js for better and worse.
// Include telemetry.js
var Telemetry = require('telemetry-js-node');
// Initialize telemetry.js just the documentation says to
Telemetry.init(function() {
// Get all versions
var versions = Telemetry.versions();
// Pick a version
var version = versions[0];
// Load measures for version
Telemetry.measures(version, function(measures) {
// Print measures available
console.log("Measures available for " + version);
// List measures
Object.keys(measures).forEach(function(measure) {
console.log(measure);
});
});
});
Whilst there certainly is some valid concerns (and risks) with loading Javascript code over http. This hack allows us to offer a stable API and minimize maintenance for people consuming the telemetry histogram aggregates. And as we’re reusing the existing code the extensive documentation for telemetry is still applicable. See the following links for further details.
Disclaimer: I know it’s not smart to load Javascript code into node.js over http. It’s mostly a security issue as you can’t use telemetry.js without internet access anyway. But considering that most people will run this as an isolated cron job (using docker, lxc, heroku or an isolated EC2 instance), this seems like an acceptable solution.
By the way, if you make a custom telemetry dashboard, whether it’s using telemetry.js in the browser or Node.js, please file a pull request against telemetry-dashboard on github to have a link for your dashboard included on telemetry.mozilla.org.
January 8, 2014 Custom Telemetry Dashboards
In the past quarter I’ve been working on analysis of telemetry pings for the telemetry dashboard, I previously outlined the analysis architecture here. Since then I’ve fixed bugs, ported scripts to C++, fixed more bugs and given the telemetry-dashboard a better user-interface with more features. There’s probably still a few bugs around, decent logging is still missing, but data aggregated is fairly stable and I don’t think we’re going to make major API changes anytime soon.
So I think it’s time to let others consume the aggregated histograms, enabling the creation of custom dashboard. In the following sections I’ll demonstrate how to get started with telemetry.js and build a custom filtered dashboard with CSV export.
Getting Started with telemetry.js
On the server-side the aggregated histograms for a given channel, version and measure is stored in a single JSON file. To reduce storage overhead we use a few tricks, such as translating filter-paths to identifiers, appending statistical fields at the end of a histogram array and computing bucket offsets from specification. This makes the server-side JSON files rather hard to read. Furthermore, we would like the flexibility to change this format, move files to a different server or perhaps do a binary encoding of histograms. To facilitate this, data access is separated from data storage with telemetry.js. This is a Javascript library to be included from telemetry.mozilla.org/v1/telemetry.js. We promise that best efforts will be made to ensure API compatibility of the telemetry.js version hosted at telemetry.mozilla.org.
I’ve used telemetry.js to create the primary dashboard hosted at telemetry.mozilla.org, so the API grants access to the data used here. I ‘ve also written extensive documentation for telemetry.js. To get you started consuming the aggregates presented on the telemetry dashboard, I’ve posted the snippet below to a jsfiddle. The code initializes telemetry.js, then proceeds load the evolution of a measure over build dates. Once loaded the code prints a histogram for each build date of the 'CYCLE_COLLECTOR' measure within 'nightly/27'. Feel free to give it a try…
Telemetry.init(function() {
Telemetry.loadEvolutionOverBuilds(
'nightly/28', // from Telemetry.versions()
'CYCLE_COLLECTOR', // From Telemetry.measures('nightly/28', callback)
function(histogramEvolution) {
histogramEvolution.each(function(date, histogram) {
print("--------------------------------");
print("Date: " + date);
print("Submissions: " + histogram.submissions());
histogram.each(function(count, start, end) {
print(count + " hits between " + start + " and " + end);
});
});
}
);
});
Warning: the channel/version string and measure string shouldn’t be hardcoded. The list of channel/versions available is returned by Telemetry.versions() and Telemetry.measure('nightly/27', callback) invokes callback with a JSON object of measures available for the given version/channel (See documentation). I understand that it can be tempting to hardcode these values for some special dashboard, and while we don’t plan to remove data, it would be smart to test that the data is available and show a warning if not. Channel, version and measure names may be subject to change as they are changed in the repository.
CSV Export with telemetry.jquery.js
One of the really boring and hard-to-get-right parts of the telemetry dashboard is the list of selectors used to filter histograms. Luckily, the user-interface logic for selecting channel, version, measure and applying filters is implemented as a reusable jQuery widget called telemetry.jquery.js. There’s no dependency on jQuery UI, just jquery.ui.widget.js which contains the jQuery widget factory. This library makes it very easy to write a custom dashboard if you just want write the part that presents a filtered histogram.
The snippet below shows how to create a histogramfilter widget and bind to the histogramfilterchange event, which is fired whenever the selected histogram is changed and loaded. With this setup you don’t need to worry about loading, filtering or maintaining state as the synchronizeStateWithHash option sets the filter-path as window.location.hash. If you want to have multiple instances of the histogramfilter widget, you might want to disable the synchronizeStateWithHash option, and read the state directly instead, see jQuery stateful plugins tutorial for how to get/set a option like state dynamically.
Telemetry.init(function() {
// Create histogram-filter from jquery.telemetry.js
$('#filters').histogramfilter({
// Synchronize selected histogram with window.location.hash
synchronizeStateWithHash: true,
// This demo fetches histograms aggregated by build date
evolutionOver: 'Builds'
});
// Listen for histogram-filter changes
$('#filters').bind('histogramfilterchange', function(event, data) {
// Check if histogram is loaded
if (data.histogram) {
update(data.histogram);
} else {
// If data.histogram is null, then we're loading...
}
});
});
The options for histogramfilter is will documented in the source for telemetry.jquery.js. This file can be found in the telemetry-dashboard repository, but it should be distributed with custom dashboards, as backwards compatibility isn’t a priority for this library. There is a few extra features hidden in telemetry.jquery.js, which let’s you implement custom <select> elements, choose useful defaults, change behavior, limit available histogram kinds and a few other things.
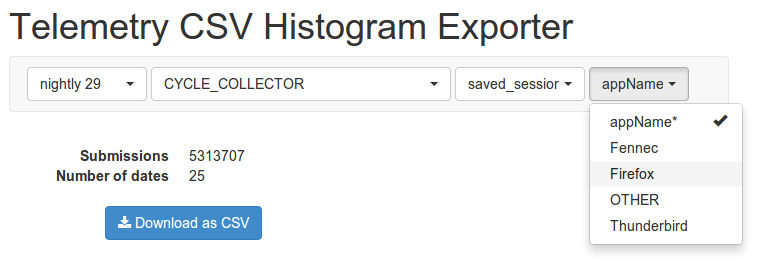 A complete custom dashboard with CSV export, minimal Javascript code and bootstrap styling, as illustrated in the screenshot above, is available at gist.github.com/jonasfj/8280124. You can fork the gist and build your custom dashboards on top of it. Gist like this can be tested using bl.ocks.org. Hence, you can try to gist above at bl.ocks.org/jonasfj/8280124. You can also build custom dashboards by forking the telemetry-dashboard repository, but the code for this dashboard is more complicated and mainly useful if you want to make a small change to the existing dashboard. In this case you can host your custom telemetry-dashboard fork using GitHub Pages, in fact mozilla.github.io/telemetry-dashboard is used as a staging area for telemetry-dashboard development.
November 8, 2013 Telemetry Rebooted: Analysis Future
A few days ago Mark Reid wrote a post on the Current State of Telemetry Analysis, and as he mentioned in the Performance meeting earlier today we’re still working on better tooling for analyzing telemetry logs. Lately, I’ve been working on tooling to analyze telemetry logs using a pool of Amazon EC2 Spot instances (tl;dr spot instance are cheaper, but may be terminated by Amazon). So far the spot based analysis framework have been deployed to generate and maintain the telemetry dashboard (hosted at telemetry.mozilla.org). I still need to create a few helper scripts, write documentation and offer an accessible way to submit new jobs, but I hope that the general developer will be able to write and submit analysis jobs in a few weeks. Don’t worry I’ll probably do another blog post when this becomes readily available.
If you’re wondering how telemetry logs end up in the cloud, take a look at Mark Reids fancy diagram in the Final Countdown. Inspired by this I decided that I too needed a fancy diagram to show how the histogram aggregations for telemetry dashboard is generated. Telemetry logs are stored in an S3 bucket in LZMA compressed blocks of at most 500 MB, the files are organized in folders by reason, application, channel, version, build date, submission date, so in practice there is a lot of small files too.
To aggregate histograms across all of these blocks of telemetry logs, the dashboard master node creates a series of jobs. Each job has a list of files from S3 to process and a pointer to code to use for processing. The jobs are pushed a queue (currently SQS) from where an auto-scaling pool of spot instances fetches jobs. When a spot worker has fetched a job it downloads the associated analysis code from a special analysis bucket, it then proceeds to download the blocks of telemetry log listed in the job, and process with the analysis code. When a spot worker completes a job, it uploads the output from the analysis code to special analysis bucket, and push an output ready message to a queue.
In the next step, the dashboard master node fetchs output ready messages from the queue, downloads the output generated by the spot worker, uses it to update the JSON histogram aggregates stored in web hosting bucket used for telemetry dashboard. From here telmetry.mozilla.org fetches the histogram aggregations and presents them to the user. The fancy diagram, below outlines the flow, dashed arrows indicates messaging and not data transfer.
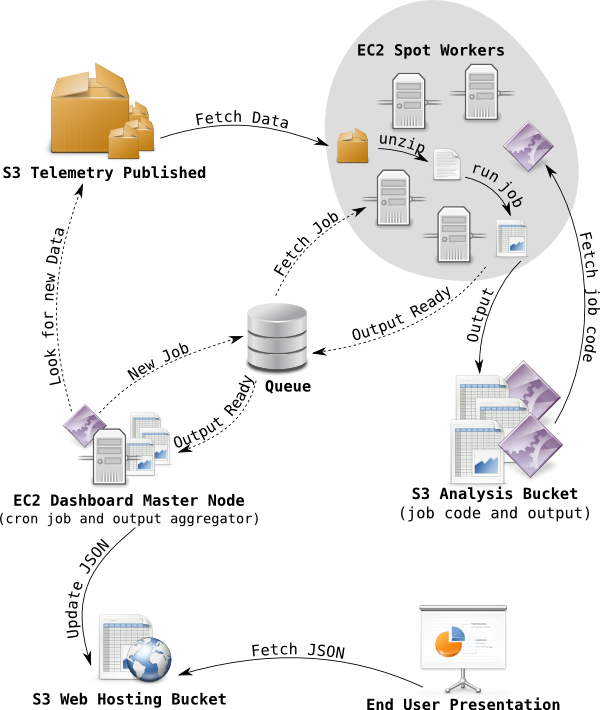
As I briefly mentioned, EC2 spot instances may be terminated by Amazon at any time, that’s why they are cheaper (approximately 20% of on-demand price). To avoid data loss the queue will retain messages after they’ve been fetched and requires messages to be deleted explicitly once processed, of the message isn’t deleted before some timeout, the message will be inserted back into the queue again. So if a spot instance gets terminated, the job will be reprocessed by another worker after the timeout.
By the way, did I mention that this framework processed one months telemetry logs, about 2 TB of LZMA compressed telemetry logs (approx. 20 TB uncompressed), in about 6 hours with 50 machines costing approximately 25 USD. So time and price wise it will be feasible to run an analysis job for a years worth of telemetry logs. The only problem I ran into with the dashboard is the fact that this resulted in 10,000 jobs, and each job created an output that the dashboard master node had to consume. The solution was to temporarily throw more hardware at the problem and run the output aggregation on my laptop. The dashboard master node is an m1.small EC2 node and it can easily keep up with day to day operations, as aggregation of one day only requires 500 jobs.
Anyways, you can look forward to the framework becoming more available in the coming weeks, so analyzing a few TB of telemetry logs will be very fast. In the mean time, checkout the telemetry dashboard at telemetry.mozilla.org, it has data since October 1st. I’ll probably get around to do a post on dashboard customization and aggregate consumption later, for those who would like to play the raw histogram aggregates beneath the current dashboard.
September 22, 2013 Model Checking Weighted Kripke Structures in the Browser
I recently graduated from Aalborg University with Master degree in Computer Science. Since then, Lars Kærlund Østergaard and I, along with our professors Jiri Srba and Kim Guldstrand Larsen published a paper on our work at SPIN 2013. Lars and I attended the conference at Stony Brook University, New York, where I presented the paper. I’ve long planned to write a series of blog posts about these things, but since I started at Mozilla I’ve been way too busy doing other interesting things. I do, however, despise the fact that my paper is hidden behind a pay-wall at Springer. So I feel compelled to use my co-author rights and release the paper here along with a few other documents, that contains proofs and results in greater detail.
Anyways, as the headline suggests this post is mainly about model checking of Weighted Computation Tree Logic (WCTL) on Weighted Kripke Structures (WKS) in a web browser. To test out the techniques we developed for local model checking, we implemented, WKTool, a browser based model checking tool, complete with graphical user-interface, syntax highlighting, inline error messages, graphical state-space exploration, and of course on-the-fly model checking using Web Workers.
If Kripke structures and branching time logics are foreign concepts to you, this post is probably of limited interest. However, if you’re familiar with the Calculus of Communicating Systems (CCS) as used in various versions of the Concurrency Workbench, this post will give an informal introduction to the syntax of the Weighted Calculus of Communicating Systems (WCCS) and WCTL as using in WKTool.
Weighted Calculus of Communicating Systems
The following table outlines the syntax for WCCS expressions. The concepts are similar to those from Concurrency Workbench, parallel composition allows input and output actions to synchronize, and restriction forces synchronization. However, it maybe observed that actions prefixes also carry a weight. This is the weight of the transition with the action is executed, on synchronization the maximum weight is used (though this is not a technical restriction).
As WCCS defines Kripke structures and not Labelled Transistion Systems (LTS) we shall also specify atomic propositions. These are also prefixed with colon, in parallel and choice composition the atomic propositions from both sub-processes are considered. In fact, the action prefix is the only construction from which atomic propositions of the sub-process isn’t considered.
Weighted Computation Tree Logic
The full syntax of WCTL is given in the help section of WKTool, conceptually there are few surprises here. WCTL features boolean operators, atomic proposition and boolean constants as expected. However, for existential and universal until modalities, WCTL adds an optional upper-bound. For example the property E a U[<=8] b holds if there exists a path such that the atomic property a holds until the atomic property b holds, and the accumulated weight at this point does not exceed 8. Similar upper-bound is available for universal until and derived modalities.
For the existential and universal weak-until modalities WCTL offers a lower-bound constraint. For example the property E a W[>=8] b holds if there exists a path such that the atomic property a always holds, or there is a path such that the atomic property a holds until the atomic property b holds and the accumulated weight at this point isn’t less than 8. Observe that the bound has no effect if there is a path where the atomic property a always holds, thus, a zero-cycle might satisfy this property.
In the examples above the nested properties are atomic, however, WKTool does in fact support nested fixed-points when the min-max encoding us used.
Weighted On-The-Fly Model Checking with WKTool
WKTool is hosted at wktool.jonasfj.dk, you can save your models to local storage (in your browser) or export them in a JSON format that can be shared or loaded later. I’m sure most of the features are easy to locate, but do notice that under “Load” > “Load Example” the 4 last examples are the scalable models used for benchmarks in our paper. Try them out, the default scaling parameters are sane and they come with properties that can be verified, some of them even have comments to help you understand what they do.
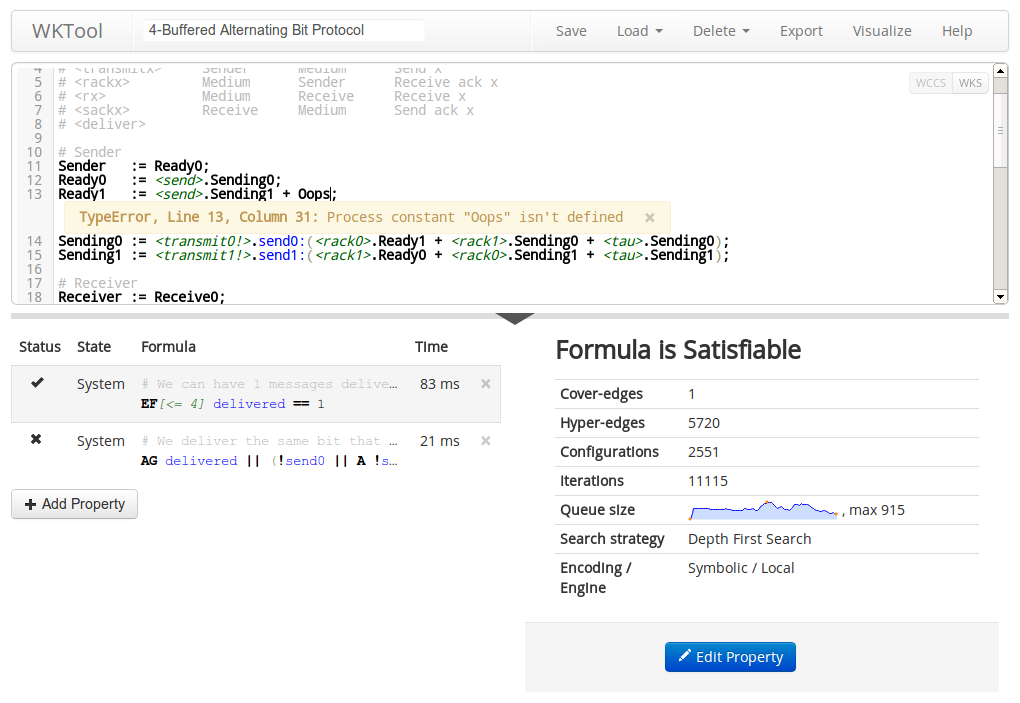
WKTool available GNU GPLv3 and the sources are hosted at github.com/jonasfj/WKTool, it’s all in CoffeeScript using PEG.js for parsers, CodeMirror with custom lexers for highlighting, Buckets.js for data structures, Arbor.js for visualization and twitter-bootstrap for awesome styling.
March 21, 2013 CodeMirror Collaboration with Google Drive Realtime Api
Yesterday morning, while lying in bed consider whether or not to face the snow outside, I saw a long anticipated entry in gReaderPro (a Google Reader app). I think the release of Google Drive Realtime Api is extremely exciting. The way I see it realtime collaboration is one of the few features that makes browser-based productivity applications preferable to conventional desktop applications.
At University I’ve been using Gobby with other students for years, with a local server the latency is zero, and whether we’re writing a paper in LaTeX or prototyping an algorithm, we’re always doing it in Gobby. It’s simply the best way to do pair programming, or to write a text together, even if you’re not always working on the same section. Futhermore, there’s never a merge conflict 🙂
Needless to say that I started reading the documentation over breakfast. And as luck would have it, Lars, who I’m writing my master with, decided that he’d rather work from home than go through the snow, saving me from having to rush out the door.
Anyways, I found sometime last night to play around with CodeMirror and the new Google Drive Realtime Api. I’ve previously had a look at Firebase, which does something similar, but Firebase doesn’t support operational transformations on strings. In Google Drive Realtime Api this is supported through the CollaborativeString object, which has events and methods for inserting text and removing ranges.
So I extended the Quickstart example to use CodeMirror for editing, after a bit of fiddling around it turned out to be quite easy to adapt the beforeChange event, such that I can all changes on the collaborativeString using insertText and removeRange methods. The following CoffeeScript snippet show how to synchronize an editor and a collaborativeString.
synchronize = (editor, coString) ->
# Assign initial value
editor.setValue coString.getText()
# Mutex to avoid recursion
ignore_change = false
# Handle local changes
editor.on 'beforeChange', (editor, changeObj) ->
return if ignore_change
from = editor.indexFromPos(changeObj.from)
to = editor.indexFromPos(changeObj.to)
text = changeObj.text.join('\n')
if to - from > 0
coString.removeRange(from, to)
if text.length > 0
coString.insertString(from, text)
# Handle remote text insertion
coString.addEventListener gapi.drive.realtime.EventType.TEXT_INSERTED, (e) ->
from = editor.posFromIndex(e.index)
ignore_change = true
editor.replaceRange(e.text, from, from)
ignore_change = false
# Handle remote range removal
coString.addEventListener gapi.drive.realtime.EventType.TEXT_DELETED, (e) ->
from = editor.posFromIndex(e.index)
to = editor.posFromIndex(e.index + e.text.length)
ignore_change = true
editor.replaceRange("", from, to)
ignore_change = false
I’ve pushed the code to github.com/jonasfj/google-drive-realtime-examples, you can also try the demo here. The demo is a markdown editor, it’ll save the file as a shortcut in Google Drive, but it’s won’t save the file as text document, just store it as a realtime document attached to the shortcut.
So a few things I learned from this exercise, use or at least study the code samples, much of it isn’t documented and the documentation can be a bit fragmented. In particular realtime-client-utils.js was really helpful to get this off the ground.
December 29, 2012 Introducing BJSON.coffee for Binary JSON Serialization
Lately, I’ve been working an web application which will need to save binary blobs inside JSON objects. Looking around the web it seems that base64 encoding is the method of choice in these cases. However, this adds a 30% overhead and decoding large base64 strings to Javascript typed arrays (ArrayBuffer) is an expensive tasks.
So I’ve been looking at different binary data formats: BSON, Protocol Buffers, Smile Format, UBJSON, BJSON and others. Eventually, I decided to give BJSON a try for the following reasons.
- BJSON is easy to make a lightweight implementation
- It can encapsulate any JSON object
- BJSON documents can be represented as JSON objects with ArrayBuffers for binary blobs.
My primary motivation is the fact that BJSON can serialize ArrayBuffers, as an added bonus a BJSON encoding of JSON object is typically smaller than the traditional string encoding with JSON.stringify(). Now, I’m sure there is valid arguments to use another binary encoding of JSON objects, so I’m going to stop with the arguments and talk code instead…
Well, time to introduce BJSON.coffee, a CoffeeScript implementation of BJSON for modern browsers. Aparts from null, booleans, numbers, arrays and dictionaries also available JSON, the BJSON specification also defines the inclusion of binary data. The specification notes that “this is not fully transcodable“, but as you might have guessed BJSON.coffee uses ArrayBuffers to represent binary data.
Essentially, BJSON.serialize takes a JSON object that is allowed to contain ArrayBuffers and serializes to a single ArrayBuffer. While, BJSON.parse takes an ArrayBuffer and returns a JSON object which may contain ArrayBuffers.For those interested in using BJSON instead of a normal string encoding of JSON objects, there is both good and bad news. The bad news is that UTF-8 string encoding in modern browsers is so slow, that BJSON is slower than a conventional string encoding of JSON objects. Although, this might not be the case when/if the string encoding specification is implemented.
The good news is that the BJSON encoding is 5-10% smaller than the conventional string encoding of JSON objects. The table/terminal output below from my testing script, shows some common JSON objects harvested from common web APIs.
Test: size (JSON): size (BJSON): Compression: Success:
bitly-burstphrases.json 17714 16372 16% true
bitly-clickrate.json 104 88 24% true
bitly-hotphrases.json 65665 60592 16% true
bitly-linkinfo.json 497 468 10% true
complex.json 424 384 25% true
flickr-hottags.json 3610 3205 11% true
twitter-search.json 12968 11994 10% true
yahoo-weather.json 1241 1172 5% true
youtube-comments.json 26296 24938 5% true
youtube-featured.json 110873 104422 5% true
youtube-search.json 93202 88473 5% true
BJSON.coffee is available at github.com/jonasfj/BJSON.coffee. It should work in all modern browsers with support for typed arrays, Firefox 15+, Chrome 22+, IE 10+, Opera 12.1+, Safari 5.1+. However, I have pushed a github page which runs unit-tests in the browser and shows compatibility results from other browsers using Browserscope. So please visit it here, click “run tests” and help figure out where BJSON.coffee works.
Update: Being bored today I decided to a quick jsperf benchmark of JSON.stringify and BJSON.serialize to see how much slower BJSON.serialize is. You can find the test here, which seems to suggest that BJSON.serialize might be unreasonably slow at the moment. However, it seems that slow UTF-8 encoding is responsible for much of this, and I believe it is possible to improve the current UTF-8 encoding speed.
December 11, 2012 Last.fm Radio API Update – Marks the end of TheLastRipper
Back in high school I started TheLastRipper, an audio stream recorder for last.fm. The project started as product for a school project on copyright and issues with piracy. It spawn from the unavailability of non-DRM infested music services. Which at the time drove many teenagers to piracy. Whilst, you the morality of recording internet radio can be argued. All the research we did at the time, showed it to be perfectly legal. Nevertheless, I’m quite happy that I didn’t have to defend this assertion.
Anyways, I’m glad to see that the music industry didn’t sleep for ever. These days we have digital music stores and I’m quite happy to pay for DRM-free music, and as bonus I get to support the artists as well. So it can hardly comes as surprise that I haven’t used TheLastRipper for years. Nor have I contributed to the project or attended bug reports for years. In fact it has been years since the project saw any active development.
I do occasionally get an email or see a bug report from an die-hard user of TheLastRipper, and it’s in the wake of such an email I’ve decide write this post. Partly because more people will ask why it stopped working, and partly because I had a lot of fun with project and it deserves a final post here at the end. Personally, I’ve long thought the project dead, I know the Linux client have been, so I was surprised to that anybody actually noticed it when the Radio API was updated.
 As you may have guessed from the title of this post TheLastRipper has died from being unmaintained while last.fm have updated their APIs. Honestly, I’m quite surprised last.fm have continued to support their old unofficial API for as long as they have. So this is by no means the result of last.fm taking action against TheLastRipper. Truth be told, I’m not even sad that it’s finally dead. The past many years, state of TheLastRipper have been quite embarrassing. The code base is ugly, buggy and completely unmaintainable.
Over the years, TheLastRipper have been downloaded more than 475.000 times, distributed with magazines (Computer Bild) and featured in countless blog posts from around the world. Which, considering that this started as a high school project is pretty good. It’s certainly been a great adventure and I’ve worked with a lot of people from around the world. So here at the of my last post on TheLastRipper, I’d like to say thanks to all the bug reporters, comment posters, testers, developers and people who hopefully also had fun participating in this project.
Oh, and to the few die-hard users out there, I’ll recommend that you buy your digital music from one of the many DRM-free music stores you can find 🙂
« Newer Posts — Older Posts »
|
|